
Jaewook Lee
NLP Application • Computer Science
View CVFields:
Natural language processing
AI
Machine Learning
Updated on Aug 09, 2025
Education
- University of Massachusetts Amherst
- Ph.D. in Computer Science (2022.9 - present)
- Advisor: Prof. Andrew Lan
- Research Area: NLP Application, Human-in-the-loop AI
- Passed Qualification Exam with distinction (2025.05)
- Korea University, Seoul, Republic of Korea
- M.E. in Electrical and Computer Engineering (2019.9 - 2022.2)
- Advisor: Prof. Seon Wook Kim
- Research Area: Compiler, Processing-in-Memory, AI framework
- Korea University, Seoul, Republic of Korea
- B.E. in Electrical Engineering (2013.3 - 2019.8)
- Graduated with honors
Work Experience
- Amazon Web Service, Seattle, WA, United States
- Applied Scientist Intern
- Developed a methodology for evaluating a multi-agent framework (details under NDA).
- Eedi, London, United Kingdom (Remote)
- Machine Learning Research Intern
- Built the prototype for AnSearch, an AI-driven math diagnostic question generator that won the Tools Competition, combining LLM speed with educator expertise to create assessments targeting common misconceptions.
Research Experience
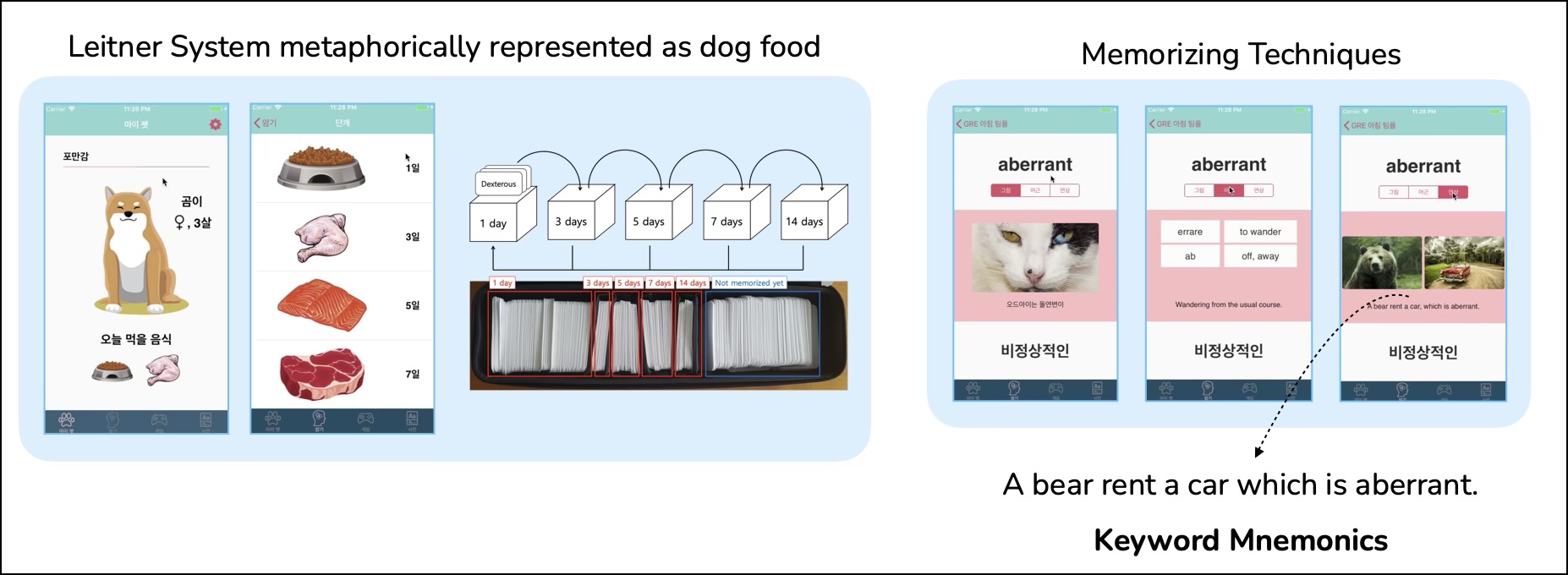
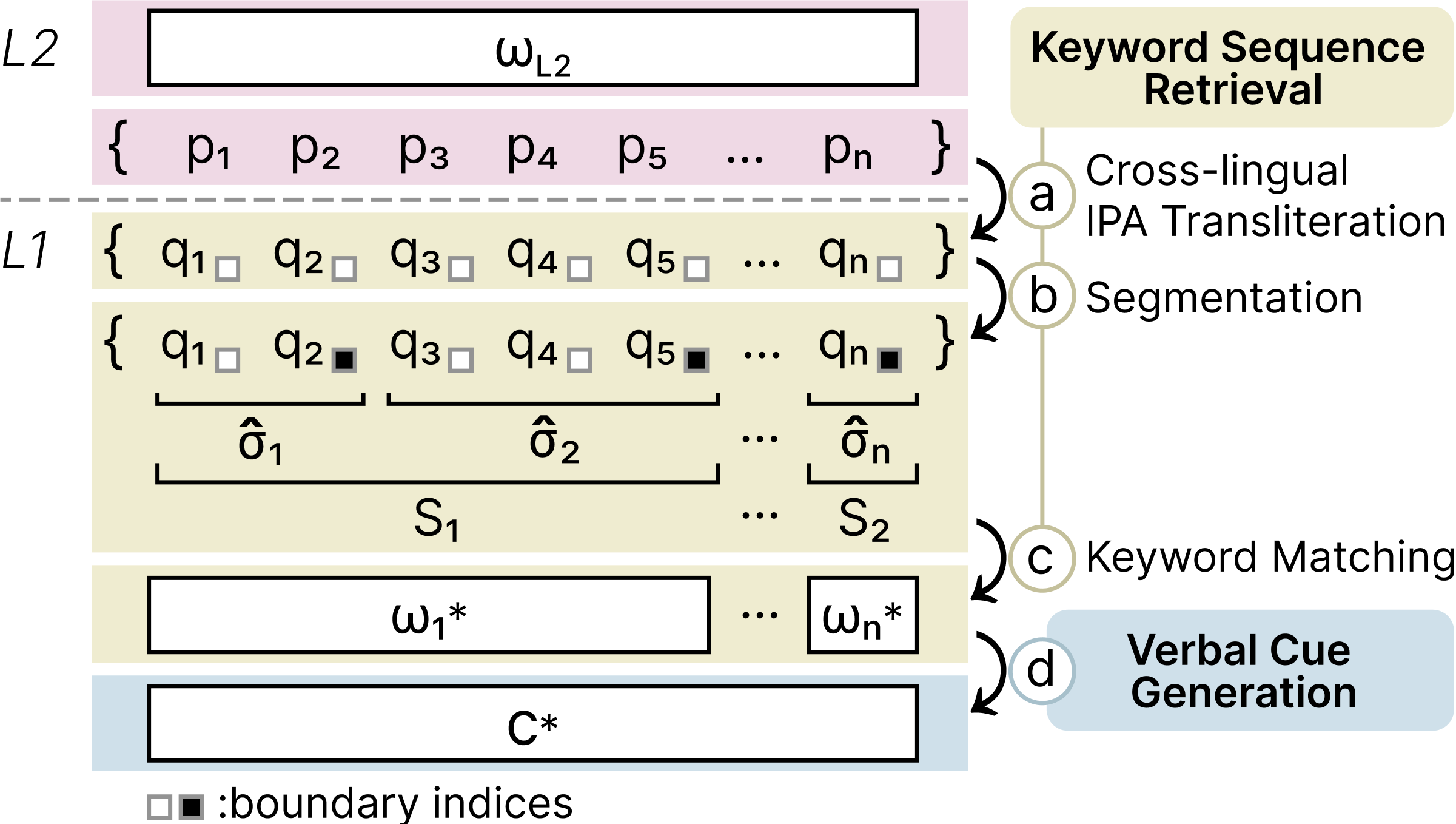
- AI for Human Creativity and Learning — Keyword Mnemonics
- Statistical modeling: Developed expectation–maximization models to learn latent user variables and generation rules for interpretable mnemonics
- Phonological similarity: Mentored and advised research on algorithms that identify phonologically similar keywords in a learner’s L1 for L2 vocabulary acquisition
- Evaluation: Designed and deployed evaluation pipelines combining psycholinguistic measures with human assessments to measure mnemonic memorability and creativity
- Multi-modal creativity: Initiated early exploration of integrating LLM-generated verbal cues with visual elements, opening a new direction for mnemonic design
- AI for Educational Assessment and Feedback — Math Education
- Training LLM-based tutors: Developed a training approach for dialogue-based tutors that optimizes tutor responses for both student correctness and pedagogical quality, using candidate generation, scoring, and preference optimization
- Automated distractor creation: Created pipelines using prompting, fine-tuning, and variational error modeling to produce plausible, targeted distractors
- Human–AI collaboration: Designed interactive authoring workflows enabling educators to refine AI-generated stems and distractors
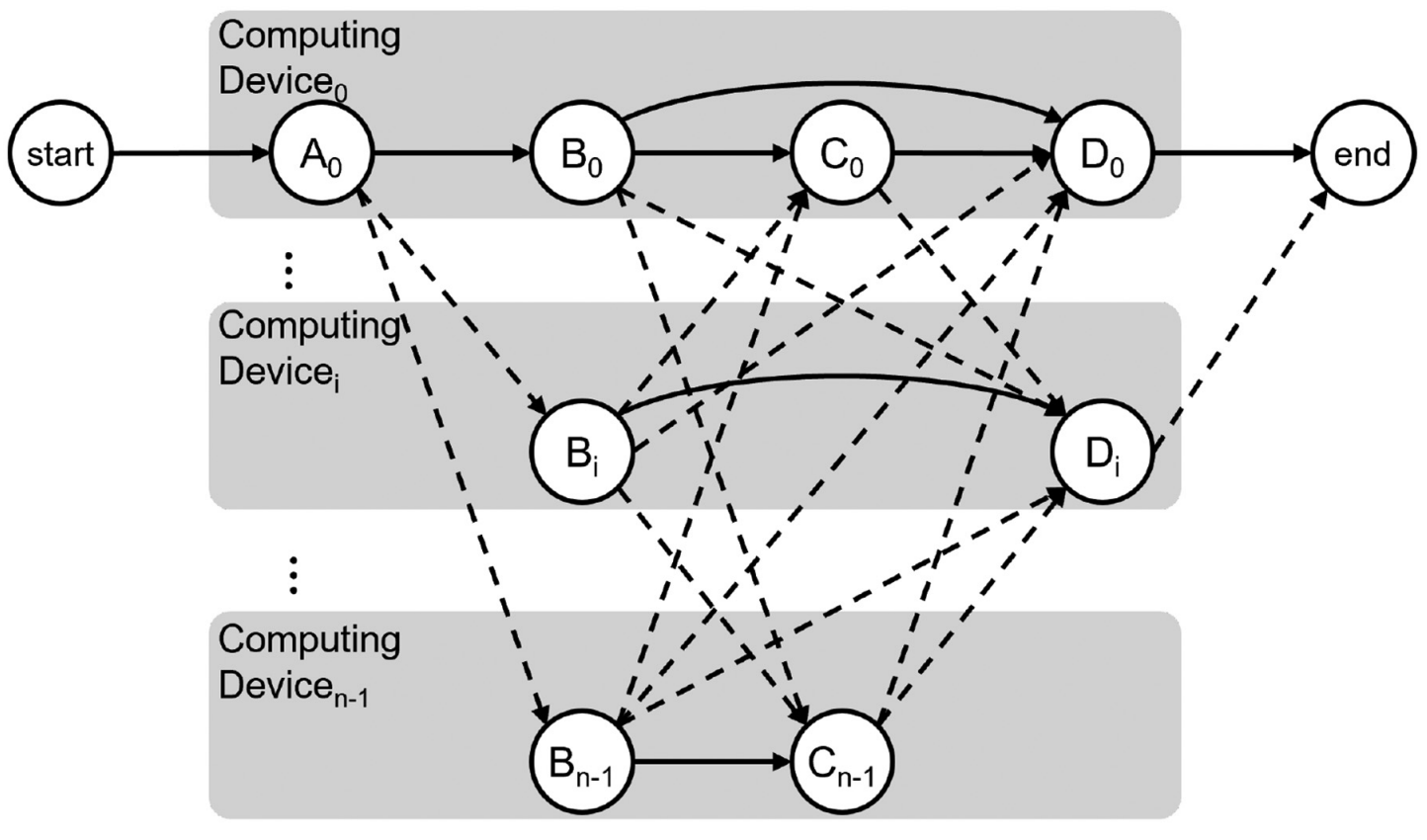
- AI Systems and Platform Optimization (Industry–Academia collaboration)
- PIM platforms: Developed ONNX Runtime integration for PIM on both x86 and ARM environments; designed profiling and scheduling algorithms to optimize DNN inference on heterogeneous PIM architectures (SK Hynix)
- Compiler-based frameworks for NPUs: Built tools to extract memory traces from DNN accelerators and modified LLVM to generate code that maximizes scratchpad memory efficiency (Samsung)
Awards
- NAEP Math Automated Scoring Challenge Grand Prize 🏆 (2023)
- Organized by National Center for Education Statistics (NCES)
- Challenge to develop an accurate, LLM-based scoring system for open-ended math responses
- NeurIPS 2022 Causal Edu Competition (Task 3) - 3rd (2022)
- Organized by EEDI
- Challenge to identify causal relationship in real-world educational time-series data
- iOS Application Hackathon Grand Prize 🏆 (2018)
- Organized by Software Technology and Enterprise, Korea University
- Developed a vocabulary builder app designed to help users efficiently memorize new words
Key Skills & Strengths
- Deep Learning
- Natural Language Processing
- Scientific Writing
- Data Analysis
- Collaboration
- Research Communication
- Python
- Experiment Design
- Critical Thinking
.png)
.jpg)
.jpg)

![[digital project] image of film festival awards](https://cdn.prod.website-files.com/6897de5d5ceaea2df1e64caa/6897f6a1265d27ca0722924e_jake_example_4.png)
![[background image] image of a work desk with a laptop and documents (for a ai legal tech company)](https://cdn.prod.website-files.com/6897de5d5ceaea2df1e64caa/6897f747a996f62b608d4373_hedge_interface%20(4).jpg)
.png)
.png)