Jaewook (Jake) Lee
NLP Application • Computer Science
View CVFields:
Natural language processing
AI
Machine Learning
Updated on Jul 03, 2026
Education
- University of Massachusetts Amherst
- Ph.D. in Computer Science (2022.9 - present)
- Advisor: Prof. Andrew Lan
- Research Area: NLP Application, Human-in-the-loop AI
- Passed Qualification Exam with distinction (2025.05)
- Korea University, Seoul, Republic of Korea
- M.E. in Electrical and Computer Engineering (2019.9 - 2022.2)
- Advisor: Prof. Seon Wook Kim
- Research Area: Compiler, Processing-in-Memory, AI framework
- Korea University, Seoul, Republic of Korea
- B.E. in Electrical Engineering (2013.3 - 2019.8)
- Graduated with honors
Work Experience
- Apple, Santa Clara, CA, United States
- Machine Learning Engineer Intern
- Contributing to multimodal search systems for Apple’s Answers, Knowledge, and Information team; additional technical details limited by confidentiality.
- Amazon Web Service, Seattle, WA, United States
- Applied Scientist Intern
- Designed the evaluation methodology for a production multi-agent AppSec framework, defining task rubrics and assessments
for design reviews, pull-request code reviews, and context-aware penetration testing.
- Eedi, London, United Kingdom (Remote)
- Machine Learning Research Intern
- Built the prototype for AnSearch, an AI-driven math diagnostic question generator that won the Tools Competition, combining LLM speed with educator expertise to create assessments targeting common misconceptions.
Research Experience
- Agentic RAG, Tool Use & Retrieval Systems
- Built an agentic RAG policy that trains LLMs with reinforcement learning to choose retrieval granularity and coordinate keyword/semantic search tools (Submitted to EMNLP 2026).
- Evaluated latency–accuracy trade-offs in software–hardware co-designed RAG, analyzing how approximate vs. exact nearest-neighbor retrieval affects time-to-first-token and downstream answer quality (Manuscript in preparation).
- Post-Training, Dialogue Systems & Model Behavior
- Developing SAE-based interpretability methods to identify latent dialogue traits and steer LLM behavior toward interpretable user characteristics (Ongoing project).
- Built an evaluation framework for LLM-simulated users in tutoring dialogues, measuring linguistic, behavioral, and cognitive realism and showing that surface-level plausibility can mask failures in learning dynamics (ACL 2026).
- Developed a preference-optimization method for deriving tutor-persona steering vectors from human tutor-student dialogues, enabling interpretable control of LLM dialogue behavior without explicit persona prompting (ACL 2026 BEA Workshop).
- Developed an Expectation Maximization-based personalization framework that infers community-level and user-specific latent preferences, enabling LLM generation under cold-start conditions (EMNLP 2025).
- Applied NLP, Personalization & Human-Centered Evaluation
- Built an iOS prototype for adaptive LLM generation that personalizes learning content to individual user preferences through
interactive feedback (CHI EA 2026 ). - Led research on phonological similarity algorithms for cross-lingual keyword discovery grounded in user language priors,
supporting personalized mnemonic generation (EMNLP 2025). - Designed evaluation pipelines combining psycholinguistic metrics with human assessment to measure memorability and creative quality in LLM-generated mnemonics (EMNLP 2024).
- Built an iOS prototype for adaptive LLM generation that personalizes learning content to individual user preferences through
- AI Systems and Platform Optimization (Industry–Academia collaboration)
- PIM platforms: Developed ONNX Runtime integration for PIM on both x86 and ARM environments; designed profiling and scheduling algorithms to optimize DNN inference on heterogeneous PIM architectures (SK Hynix)
- Compiler-based frameworks for NPUs: Built tools to extract memory traces from DNN accelerators and modified LLVM to generate code that maximizes scratchpad memory efficiency (Samsung)
Awards
- NAEP Math Automated Scoring Challenge Grand Prize 🏆 (2023)
- Organized by National Center for Education Statistics (NCES)
- Challenge to develop an accurate, LLM-based scoring system for open-ended math responses
- NeurIPS 2022 Causal Edu Competition (Task 3) - 3rd (2022)
- Organized by EEDI
- Challenge to identify causal relationship in real-world educational time-series data
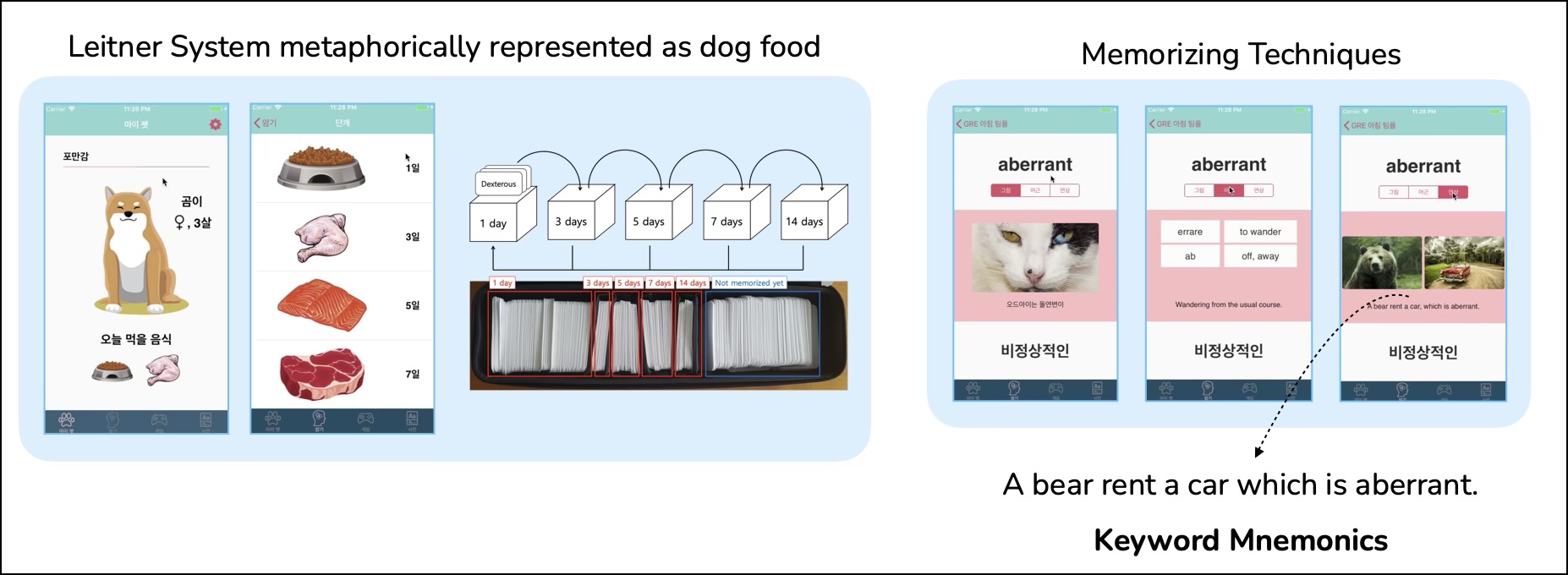
- iOS Application Hackathon Grand Prize 🏆 (2018)
- Organized by Software Technology and Enterprise, Korea University
- Developed a vocabulary builder app designed to help users efficiently memorize new words
Key Skills & Strengths
- Deep Learning
- Natural Language Processing
- Scientific Writing
- Data Analysis
- Collaboration
- Research Communication
- Python
- Experiment Design
- Critical Thinking